Reality is not a ____
En cours d’écriture
Avec la mouvance NoSQL, cela fait maintenant quelques temps que l’on entend un peu partout que le modèle relationnel est trop pauvre (pour ceux qui offrent un modèle plus riche) ou trop riche (pour ceux qui offrent un modèle plus pauvre).
Et donc en fonction de l’usage prévu, il va falloir choisir à l’inception d’un projet le modèle de données que l’on va utiliser pour représenter le domaine et le système de gestion de ce modèle qui va avec 1.
Bravo, et comme nous sommes world class modeler (si vous ne l’êtes pas, vous allez le devenir), nous allons tordre la donnée de notre domaine pour qu’elle rentre dans le modèle de données choisi en optimisant selon quelques critères :
- La minimisation du nombre de ____.
- La maximisation du nombre de résultat sans ____ 2 .
- un ou deux critéres en fonction de ce qu’il y a à la mode en ce moment.
Et c’est très intéressant comme méthode, c’est comme ça que l’on s’est retrouvé avec 40ans de SQL, pour :
- minimiser la place nécessaire pour le modèle,
- maximiser le nombre de résultat sans inférence (via les jointure)
Quand le modèle fut bien déployé, on a maximisé la réutilisation d’un modèle déjà connu …
Rasoir d’Occam
Le principal problème avec les modèles de données est qu’il ont trop de responsabilité?
- d’accumuler les observations sur le domaine modélisé
- et de fournir une représentation.
Les représentations sont systèmatiquements fauses (mais parfois utiles), et la façon de faire des observations changent avec le temps.
Si l’on veut évoluer dans la modèlisation, il faut faire la ségrégation de l’observation du domaine dans les modèles, des représentations.
Un exemple avec du “code”
Pour aider à comprendre la différence entre l’observation dans un modèle et la représenation, je vous propose un peu de Scala.
Ceci est un block qui renvoit la valeur “MONDE” (un block en Scala retourne la dernière expression).
{
val a = "monde"
a.toUpperCase
}
Voici l’arbre syntaxique abstrait (simplifié) de ce block (Observation du block) :
Block(
// définition de la valeur
ValDef(
newTermName("a")
, Literal("monde")
)
// application de la méthode
, Apply(
newTermName("a")
, newTermName("toUpperCase")
)
)
Voici la représentation classique du block ici pour l’execution, après les différentes phases du compilateur :
Constant pool:
#14 = Utf8 ()Ljava/lang/String;
#15 = Utf8 monde
#16 = String #15 // monde
#17 = Utf8 LineNumberTable
#18 = Utf8 java/lang/String
#19 = Class #18 // java/lang/String
#20 = Utf8 toUpperCase
#21 = NameAndType #20:#14 // toUpperCase:()Ljava/lang/String;
#22 = Methodref #19.#21 // java/lang/String.toUpperCase:()Ljava/lang/String;
{
Code:
stack=1, locals=1, args_size=1
0: ldc #16 // String Monde
2: astore_1
3: aload_1
4: invokevirtual #22 // Method java/lang/String.toUpperCase:()Ljava/lang/String;
7: areturn
}
Et voici une autre des représentations possibles est un graphe où newTermName("a") est un noeud, lié à Literal(Constant("monde")), à l’application avec la fonction"toUpperCase" ….
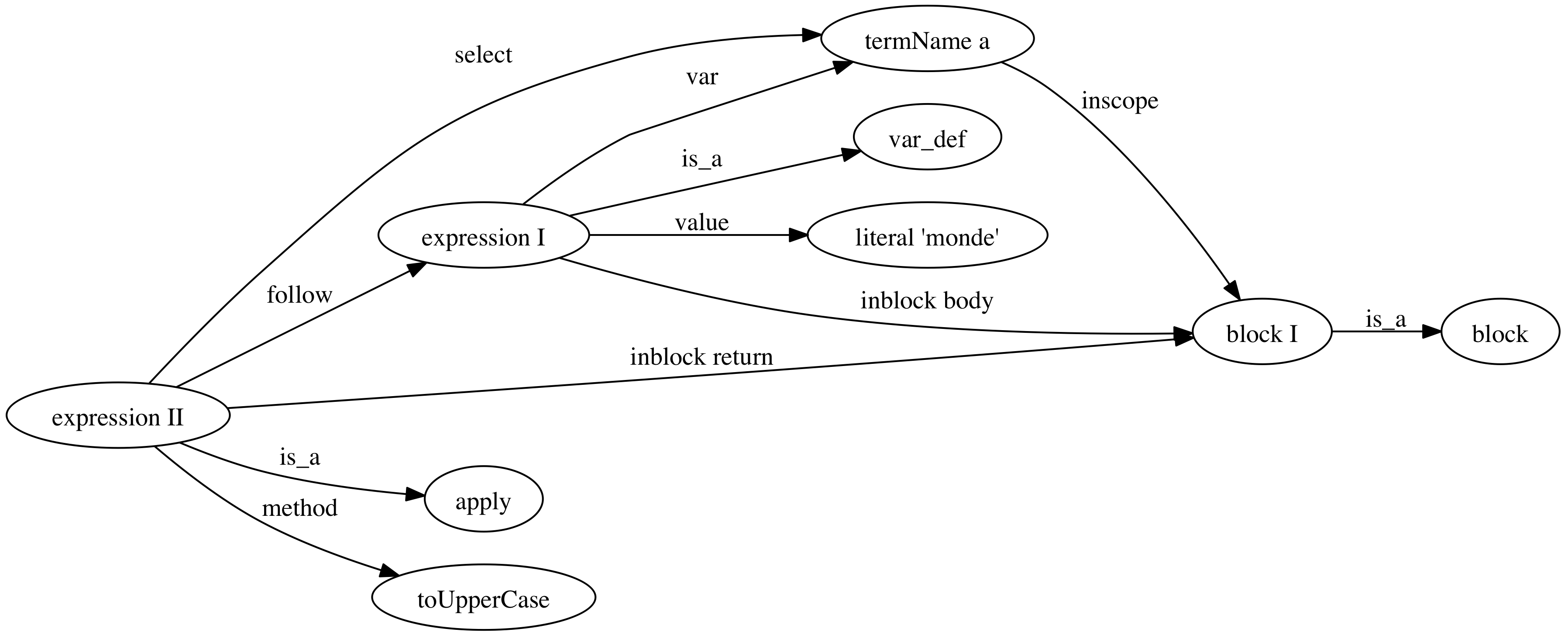
(On peut aller voir du coté de Codeq pour ça, c’est très intéressant : http://blog.datomic.com/2012/10/codeq.html )
On a ici à partir d’une seule observation du code Scala (l’AST), dont les noeuds sont indépendants entre eux (il n’y pas plus d’informations que la structure et le contenu de chaque noeud), deux représentations ad hoc du monde pour des usages différents.
Ici, on a séparé le modèle du code (AST) de ses représentations pour des usages particuliers (execution / analyse).
Le cas des compilateurs et langages
blog comments powered by Disqus